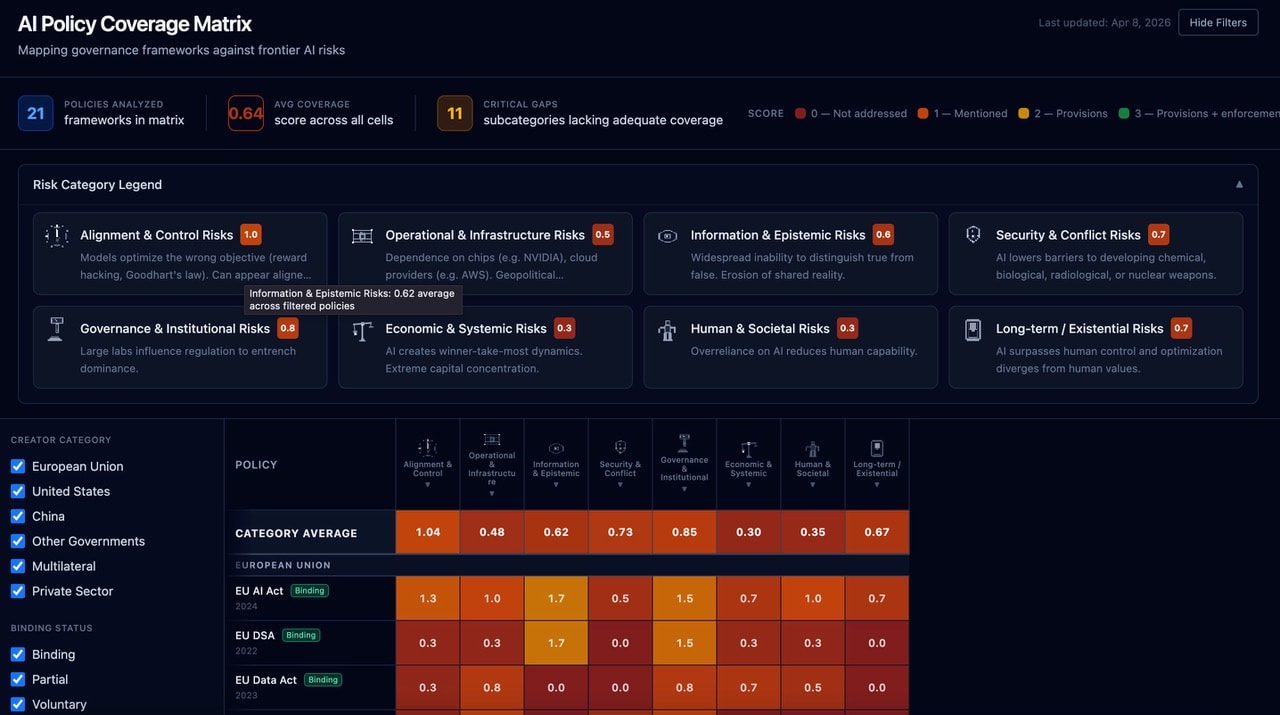
Summary: We are on the precipice of unprecedented AI capability - so I wanted to understand in greater detail what policy and governance measures are in place, and how adequately they cover major risks. I scored 21 AI governance instruments against 29 risk subcategories on a 0–3 scale: 0 meaning the risk is entirely unaddressed, 1 that it is referenced, 2 that some provisions for risk mitigation are included, and 3 that provisions and enforcement mechanisms are put forward. The average score across all risk categories is 0.64/3.0. Economic and societal risks are currently almost entirely unaddressed by existing AI governance frameworks. Enforcement mechanisms are nearly nonexistent. And the strongest coverage of frontier-relevant risks comes from corporate self-governance - which is, by design, voluntary and unilateral. The full interactive matrix can be found here. This post presents the key findings.
The exercise
There are now enough AI governance instruments — regulations, voluntary frameworks, corporate commitments, multilateral declarations — that nobody can hold them all in their head at once. But “there’s a lot of governance activity” and “governance is adequate” are very different claims, and I wanted to build greater clarity around where we sit on this spectrum. This feels particularly urgent as a new generation of AI models (OpenAI’s ‘Spud’ and Anthropic’s Mythos) approaches release, bringing us materially closer to capability levels where governance gaps translate into real-world harm rather than theoretical risk.
So I built a structured comparison. I took 21 prominent governance instruments - the EU AI Act, NIST AI RMF, Anthropic’s RSP, the Bletchley Declaration, and 17 others — selected for prominence, geographic diversity, and relevance to frontier AI. I scored each one against a taxonomy of 29 risk subcategories grouped into eight domains. The scoring uses a conservative four-point rubric:
- 0 — Not addressed: No mention.
- 1 — Mentioned: Acknowledged in preamble or principles, but no operative provisions.
- 2 — Provisions: Specific requirements, guidelines, or recommended practices.
- 3 — Provisions + enforcement: Specific provisions backed by audits, penalties, licensing, or oversight bodies.
Two methodological choices are worth flagging upfront. First, I scored what instruments mandate, not what they imply. Aspirational language in a preamble gets a 1 at most. This is conservative by design - I’d rather undercount coverage than overcount it. Second, a 0–3 rubric necessarily compresses nuance. It cannot distinguish between a well-drafted provision and a poorly drafted one at the same score level. But the purpose here is to reveal structural patterns in coverage instead of evaluating the quality of the policy itself. For that purpose, the rubric is sufficient. The underlying scores, excerpts, and reasoning are all published alongside the matrix for scrutiny.
Finding 1: The gap is enormous
Across all 609 subcategory-level cells (21 instruments × 29 subcategories), the average score is 0.64 out of 3.0. Aggregated to the category level (21 instruments × 8 risk domains), the distribution is:
Share of cells:
- 0 (Not addressed): 58%
- 1 (Mentioned only): 30%
- 2 (Substantive provisions): 10% 3
- 3 (Provisions + enforcement): 2%
The dominant mode of existing AI governance is acknowledgement without action. Nearly nine in ten policy-risk intersections involve either silence or non-operative language.
Eleven specific risk subcategories receive near-zero coverage across all 21 instruments. These include autonomous escalation protocols, deceptive alignment monitoring, capability atrophy safeguards, macroprudential AI regulation, and crisis coordination mechanisms. These aren’t obscure risks, but rather substantial, high impact possible risk vectors that appear regularly in technical safety research and strategic assessments that currently have no clear governance home within existing prominent AI policy.
Finding 2: Coverage clusters around risks that map to existing institutional capabilities
Category-level averages reveal where governance attention concentrates.
Risk category average score:
- Alignment & Control - 1.04
- Governance & Institutional - 0.85
- Security & Conflict - 0.73
- Long-term / Existential - 0.67
- Information & Epistemic - 0.62
- Operational & Infrastructure - 0.48
- Human & Societal - 0.35
- Economic & Systemic - 0.30
The emerging pattern isn’t random, but reflects that risks that can be addressed through tools already available to the actors writing governance, such as safety evaluations, red-teaming, model cards, disclosure requirements, attract more attention than risks requiring cross-sectoral institutional response. Alignment risks map to things AI labs already do. Labour displacement and cognitive atrophy, by contrast, are measurable but demand coordinated action across labour ministries, education systems, and social safety nets - institutional infrastructure that doesn’t yet exist for AI-specific harms.
Governance currently follows institutional capability as opposed to risk magnitude.
Even the highest-scoring category (Alignment & Control, 1.04) barely exceeds the threshold for “mentioned.” No risk domain receives consistently substantive governance attention across the full instrument set.
Finding 3: Corporate self-governance creates a false sense of coverage
This is the finding I find most interesting and most concerning.
Anthropic’s Responsible Scaling Policy scores 2.3 on Alignment & Control and 2.3 on Security & Conflict - the highest scores anywhere in the matrix. DeepMind’s Frontier Safety Framework matches this. OpenAI’s Preparedness Framework is close behind at 2.0 on Security & Conflict.
Compare this with the EU AI Act: 1.3 on Alignment & Control, 0.5 on Security & Conflict. The most comprehensive binding regulation in the world is outperformed on frontier-relevant safety risks by voluntary corporate commitments.
But now look at the other side. On Economic & Systemic risks: Anthropic RSP scores 0.3, DeepMind FSF scores 0.0. On Human & Societal risks: both score 0.3. On Governance & Institutional risks - which includes regulatory capture and lab concentration, things that directly implicate these companies - Anthropic scores 1.3, DeepMind 1.0.
This creates a structural problem that goes beyond the obvious fact that “companies won’t regulate themselves.” Corporate frameworks are visibly strong on technical safety, which are the risks that currently attract most public attention and researcher scrutiny, which produces an impression of more comprehensive coverage. The matrix shows that this impression is misleading. The risks these frameworks address well are precisely the risks that overlap with the labs’ commercial interests (safe deployment enables continued scaling). The risks they ignore are those where the labs are part of the problem, such as market concentration, labour displacement, institutional capture.
No company is going to write binding provisions about its own market concentration. This isn’t a criticism of any individual lab’s good faith. It’s a structural observation about what self-governance can and cannot do.
The implication is that effective governance needs technically specific private-sector commitments integrated with publicly accountable institutional oversight. Neither alone is sufficient. The current landscape has both, but in a parallel non-integrated manner. The institutional connector is missing.
Finding 4: Enforcement barely exists - and this is the binding constraint
Only 2% of cells score 3 (provisions with enforcement). Those are concentrated almost entirely in the EU AI Act (conformity assessments, penalties for prohibited practices) and the EU DSA.
It is worth noting that a score of 3 is not to say that a policy is a good or effective policy - just that it makes an effort at establishing enforceable provisions to mitigate a risk category. It is a reflection of intent as opposed to efficacy. Nevertheless, no voluntary framework achieves a score of 3 on any subcategory. No corporate instrument does either.
This means that even where risks are substantively addressed (score 2), compliance is effectively optional. The practical difference between a mandatory instrument without enforcement and a voluntary instrument with detailed provisions is smaller than the formal classification suggests.
The marginal value of producing more voluntary frameworks, more declarations of principles, more corporate commitments is low. What’s scarce isn’t recognition of risks, but rather the institutional machinery to monitor, audit, and sanction which thus far has remained scarce.
What would effective enforcement actually look like for frontier AI? The closest analogy may be nuclear safety inspection with mutual access agreements where regulators maintain technical staff capable of evaluating labs’ internal safety work, with the authority to mandate operational changes. The IAEA model isn’t a perfect fit (AI labs are private companies, not state programmes), but the core principle of ensuring verified trust rather than declared trust is directly applicable. Nothing in the current governance landscape comes close to this.
Finding 5: Governance taxonomies can’t keep pace with capability development
Two emerging risk areas - autonomous agentic systems and international crisis coordination for AI incidents - don’t fit cleanly into any existing subcategory in the matrix. This isn’t just a limitation of my taxonomy. It reflects a deeper problem; that the governance instruments themselves don’t yet recognise these as distinct risk categories.
- Autonomous agents that can take consequential real-world actions, such as booking flights, writing code, managing finances, operating infrastructure are rapidly being deployed for business and personal use. This reality, along with the growing capability of the underlying LLM systems that power them, challenge governance frameworks designed around model deployment and static outputs. The regulatory question shifts from “is this model safe to release?” to “what happens when this model acts in the world unsupervised?” No existing instrument addresses this coherently.
- Crisis coordination (i.e. establishing protocols for cross-jurisdictional response to AI-related emergencies) lacks any existing institutional home. If an AI system caused a major incident affecting multiple countries tomorrow, there is no standing mechanism for coordinated response. Compare this with aviation (ICAO), nuclear incidents (IAEA), or financial crises (FSB) - all have crisis coordination protocols developed before, not after, a major incident.
This ultimately constitutes a major governance lag: the gap between the pace at which AI capabilities create new risk categories and the pace at which governance taxonomies update to recognise them. The EU AI Act took roughly three years from proposal to enforcement. GPT-4 to autonomous agent deployment took roughly two. The lag is structural and, on current trends, growing. The matrix makes this lag visible - which is part of its purpose.
Conclusions and Actionable Insights
As things currently stand we are leaving the eventual impact of all covered risk categories to some combination of good luck, the capacity of non-AI policies and institutions to be sufficiently flexible and applicable to AI risk categories, and the good will of AI companies to continue strengthening and adhering to their own voluntary safety frameworks.
These are risks which stretch far beyond AI and touch all elements of human society. I wouldore urgent, rigorous steps are needed to close the gap.
Three implications feel actionable:
For policymakers: The deepest red in the matrix - Economic & Systemic, Human & Societal, Operational & Infrastructure - represents the highest marginal return on new governance investment. These categories need new governance modalities, not extensions of existing ones. Concretely: a macroprudential approach to AI might involve mandatory reporting of AI-driven workforce changes above a threshold (analogous to large-exposure reporting in banking), adaptive regulatory triggers that activate new provisions when capability benchmarks are crossed, and standing institutional capacity to monitor systemic concentration in AI infrastructure. None of these exist today.
For the AI safety community: The structural asymmetry finding should inform how we think about governance strategy. Pushing labs to strengthen their voluntary commitments has diminishing returns if those commitments systematically exclude systemic risks. The leverage point is integration mechanisms or formal structures that connect private technical expertise with public accountability. What does the institutional connector between Anthropic’s RSP and the EU AI Act actually look like? I see that as a key design problem worth working on.
For researchers: Eleven critical gaps with near-zero coverage across all instruments represent high-value targets for policy-relevant research. If you’re looking for a governance research question where your work could directly inform new policy, the matrix provides a menu.
The tool
The full interactive matrix is at ai-policy-visualisation.vercel.app. You can filter by issuer type, binding status, and risk category. Hovering over any cell shows the textual excerpts that informed the score. The scoring framework and source data are published alongside it.
This is designed as a living tool. I’ll update it as instruments evolve and new ones emerge. If you disagree with a score, I want to hear about it — the methodology is transparent precisely so it can be challenged and improved.
A longer working paper with full methodology, related work, and detailed findings will shortly be made available